This refactors the front-end collateral to all live within `site` - so no `package.json` at the root.
The reason we had this initially is that the jest test run and NextJS actually require having _two_ different `tsconfig`s - Next needs `jsx:"preserve"`, while jest needs `jsx:"react"` - we were using `tsconfig`s at different levels at the hierarchy to manage this.
I changed this behavior to still use two different `tsconfig.json`s, which is mandatory - but just side-by-side in `site`.
Once that's fixed, it was easy to move everything into `site`
Follow up from: https://github.com/coder/coder/pull/118#discussion_r796244577
This brings an async service that parses and
provisions to life! It's separated from coderd
intentionally to allow for simpler testing.
Integration with coderd will come in another PR!
@kylecarbs and I were debugging a gnarly postgres issue over the weekend, and unfortunately it looks like it is still coming up occassionally: https://github.com/coder/coder/runs/5014420662?check_suite_focus=true#step:8:35 - so thought this might be a good testing Monday task.
Intermittently, the test would fail with something like a `401` - invalid e-mail, or a `409` - initial user already created. This was quite surprising, because the tests are designed to spin up their own, isolated database.
We tried a few things to debug this...
## Attempt 1: Log out the generated port numbers when running the docker image.
Based on the errors, it seemed like one test must be connecting to another test's database - that would explain why we'd get these conflicts! However, logging out the port number that came from docker always gave a unique number... and we couldn't find evidence of one database connecting to another.
## Attempt 2: Store the database in unique, temporary folder.
@kylecarbs and I found that the there was a [volume](https://github.com/docker-library/postgres/blob/a83005b407ee6d810413500d8a041c957fb10cf0/11/alpine/Dockerfile#L155) for the postgres data... so @kylecarbs implemented mounting the volume to a unique, per-test temporary folder in https://github.com/coder/coder/pull/89
It sounded really promising... but unfortunately we hit the issue again!
### Attempt 3... this PR
After we hit the failure again, we noticed in the `docker ps` logs something quite strange:

When the docker image is run - it creates two port bindings, an IPv4 and an IPv6 one. These _should be the same_ - but surprisingly, they can sometimes be different. It isn't deterministic, and seems to be more common when there are multiple containers running. Importantly, __they can overlap__ as in the above image.
Turns out, it seems this is a docker bug: https://github.com/moby/moby/issues/42442 - which may be fixed in newer versions.
To work around this bug, we have to manipulate the port bindings (like you would with `-p`) at the command line. We can do this with `docker`/`dockertest`, but it means we have to get a free port ahead of time to know which port to map.
With that fix in - the `docker ps` is a little more sane:

...and hopefully means we can safely run the containers in parallel again.
Use the native 'concurrency' configuration feature to cancel
concurrent builds, rather than the cancel-workflow-action.
This also allows us to reduce permissions for the workflow.
* fix: Synchronize peer logging with a channel
We were depending on the close mutex to properly
report connection state. This ensures the RTC
connection is properly closed before returning.
* Disable pion logging
* Remove buffer
* Try ICE servers
* Remove flushed
* Add diagram explaining handshake
* Fix candidate accept ordering
* Add debug logging to peerbroker
* Fix send ordering
* Lock adding ICE candidate
* Add test for negotiating out of order
* Reduce connection to a single negotiation channel
* Improve test times by pre-installing Terraform
* Lock remote session description being applied
* Organize conn
* Revert to multi-channel setup
* Properly close ICE gatherer
* Improve comments
* Try removing buffered candidates
* Buffer local and remote messages
* Log dTLS transport state
* Add pion logging
Having a mixture of abbreviations in the codebase reduces
clarity. Although opts is common for options, I'd rather
set a precedent of clarifying verbosity.
When using parallel before, multiple PostgreSQL containers would
unintentionally interfere with the other's data. This ensures
both containers have separated data, and don't create a volume.
🌮 @bryphe-coder for the idea!
* feat: Add parameter and jobs database schema
This modifies a prior migration which is typically forbidden,
but because we're pre-production deployment I felt grouping
would be helpful to future contributors.
This adds database functions that are required for the provisioner
daemon and job queue logic.
* feat: Compute project build parameters
Adds a projectparameter package to compute build-time project
values for a provided scope.
This package will be used to return which variables are being
used for a build, and can visually indicate the hierarchy to
a user.
* Fix terraform provisioner
* feat: Add provisionerd protobuf definitions
Provisionerd communicates with coderd over a multiplexed
WebSocket serving dRPC. This adds a roughly accurate protocol
definition.
It shares definitions with "provisioner.proto" for simple
interop with provisioners!
* feat: Add parameter and jobs database schema
This modifies a prior migration which is typically forbidden,
but because we're pre-production deployment I felt grouping
would be helpful to future contributors.
This adds database functions that are required for the provisioner
daemon and job queue logic.
* feat: Compute project build parameters
Adds a projectparameter package to compute build-time project
values for a provided scope.
This package will be used to return which variables are being
used for a build, and can visually indicate the hierarchy to
a user.
* Fix terraform provisioner
* Improve naming, abstract inject to consume scope
* Run CI on all branches
* feat: Add parameter and jobs database schema
This modifies a prior migration which is typically forbidden,
but because we're pre-production deployment I felt grouping
would be helpful to future contributors.
This adds database functions that are required for the provisioner
daemon and job queue logic.
* Add comment to acquire provisioner job query
* PostgreSQL hates running in parallel
* chore: Update pion/ice fork to resolve goroutine leak
* Flush remote too
* Add logs for setting the description
* Try locking only on remote
* Remove local bufferring in favor of remote
* Remove unused flush func
* Set candidates flushed to true
* Defer flush until the end of negotiation
* Buffer ICE candidates
* Add comment clarifying channel buffer
* Flush after handshake
* Move away from fork
* Ignore pion/ice leaks
* chore: Buffer remote candidates like local
This was added for local candidates, and is required for remote
to prevent a race where they are added before a negotiation is
complete.
I removed the mutex earlier, because it would cause a different race.
I didn't realize the remote candidates wouldn't be buffered,
but with this change they are!
* Use local description instead
* Add logging for candidate flush
* Fix race with atomic bool
* Simplify locks
* Add mutex to flush
* Reset buffer
* Remove leak dependency to limit confusion
* Fix ordering
* Revert channel close
* Flush candidates after remote session description is set
* Bump up count to ensure race is fixed
* Use custom ICE dependency
* Fix data race
* Lower timeout to make for fast CI
* Add back mutex to prevent race
* Improve debug logging
* Lock on local description
* Flush local candidates uniquely
* Fix race
* Move mutex to prevent candidate send race
* Move lock to handshake so no race can occur
* Reduce timeout to improve test times
* Move unlock to defer
* Use flushed bool instead of checking remote
* chore: Fix race in collecting ICE Candidates
This logic was flawed previously. ICE Candidates could collect
before a negotiation was triggered, which led to a race where
candidates would be lost. Candidates can no longer be lost,
and we removed some code 😎.
* Add comment describing fix
* Use upstream dependency to fix goroutine leak
* Use upstream dependency to fix goroutine leak
Previously, there was a pseudo-workspaces page that was leftover from prototyping, but doesn't make sense in the revised flow.
Now, we have a `/projects` page, and after logging in, the user should be taken to that page:
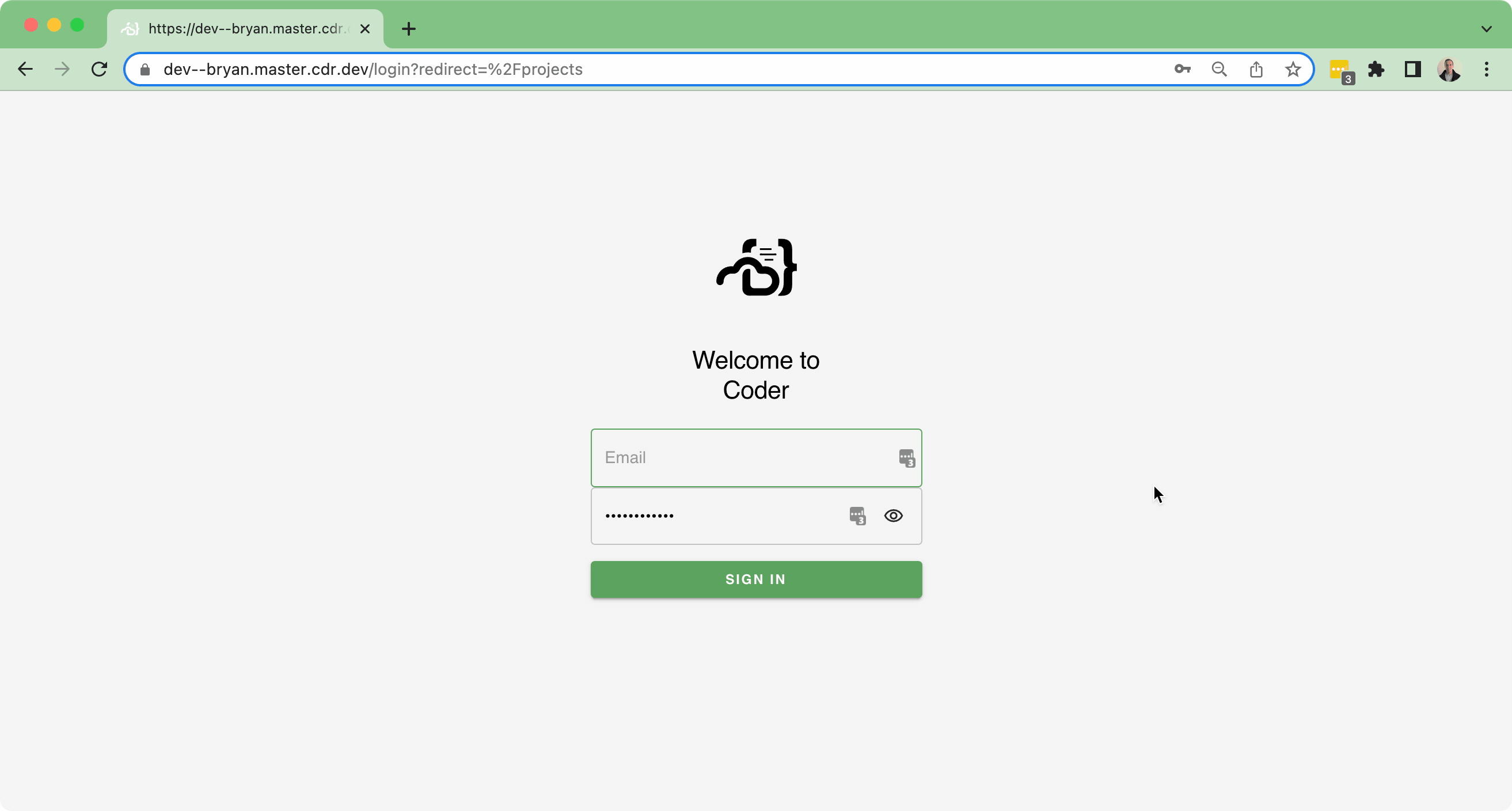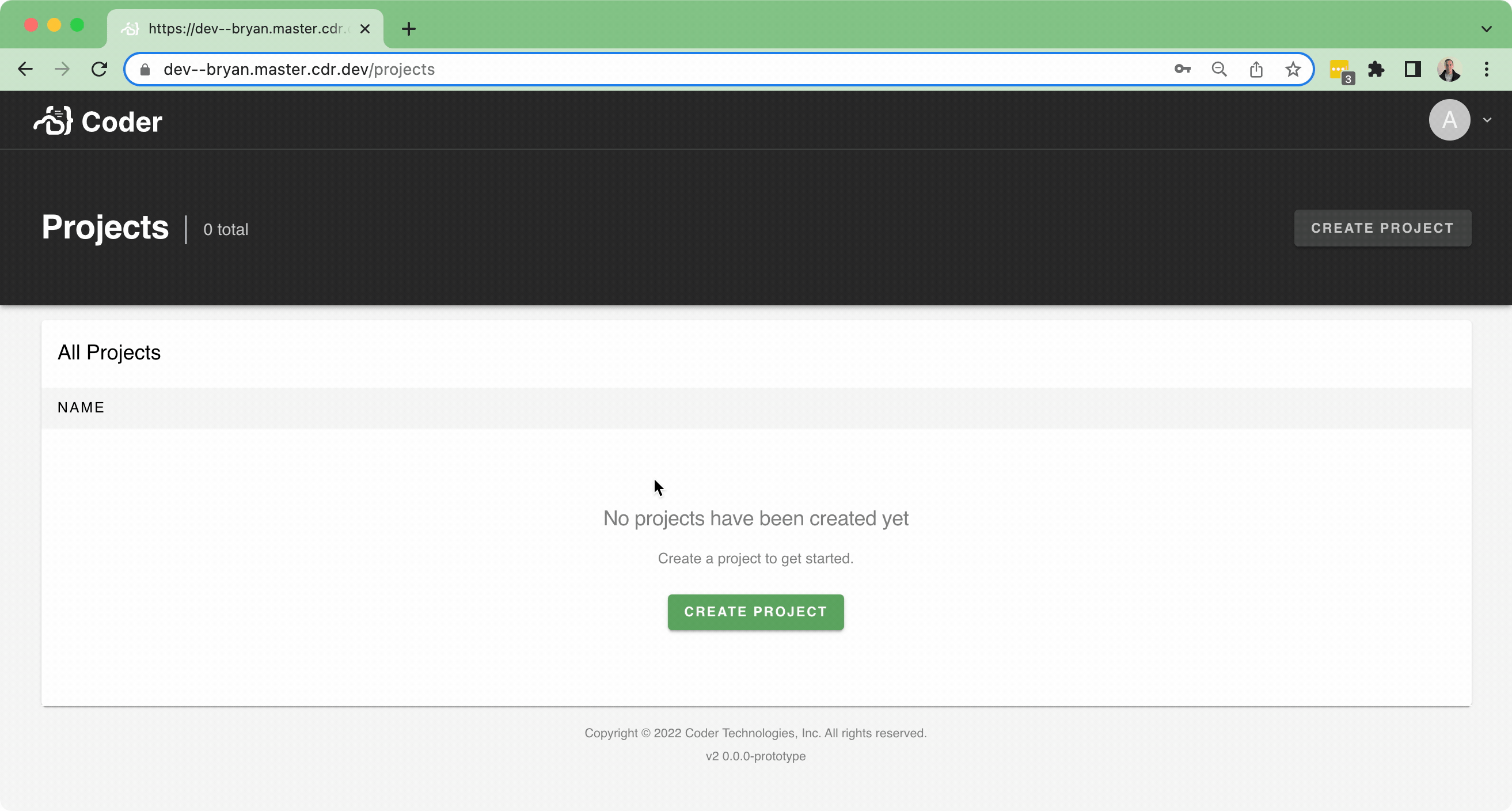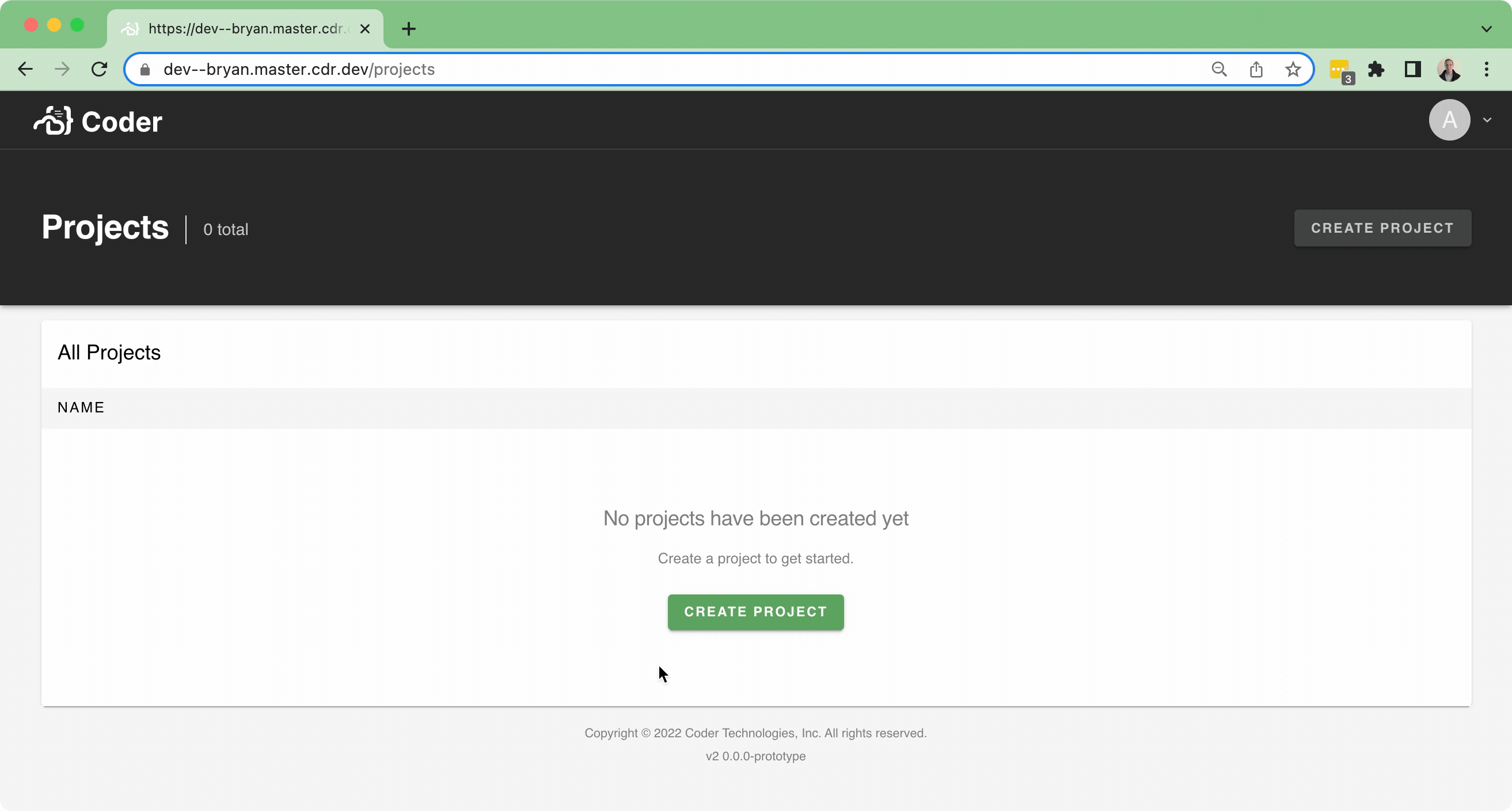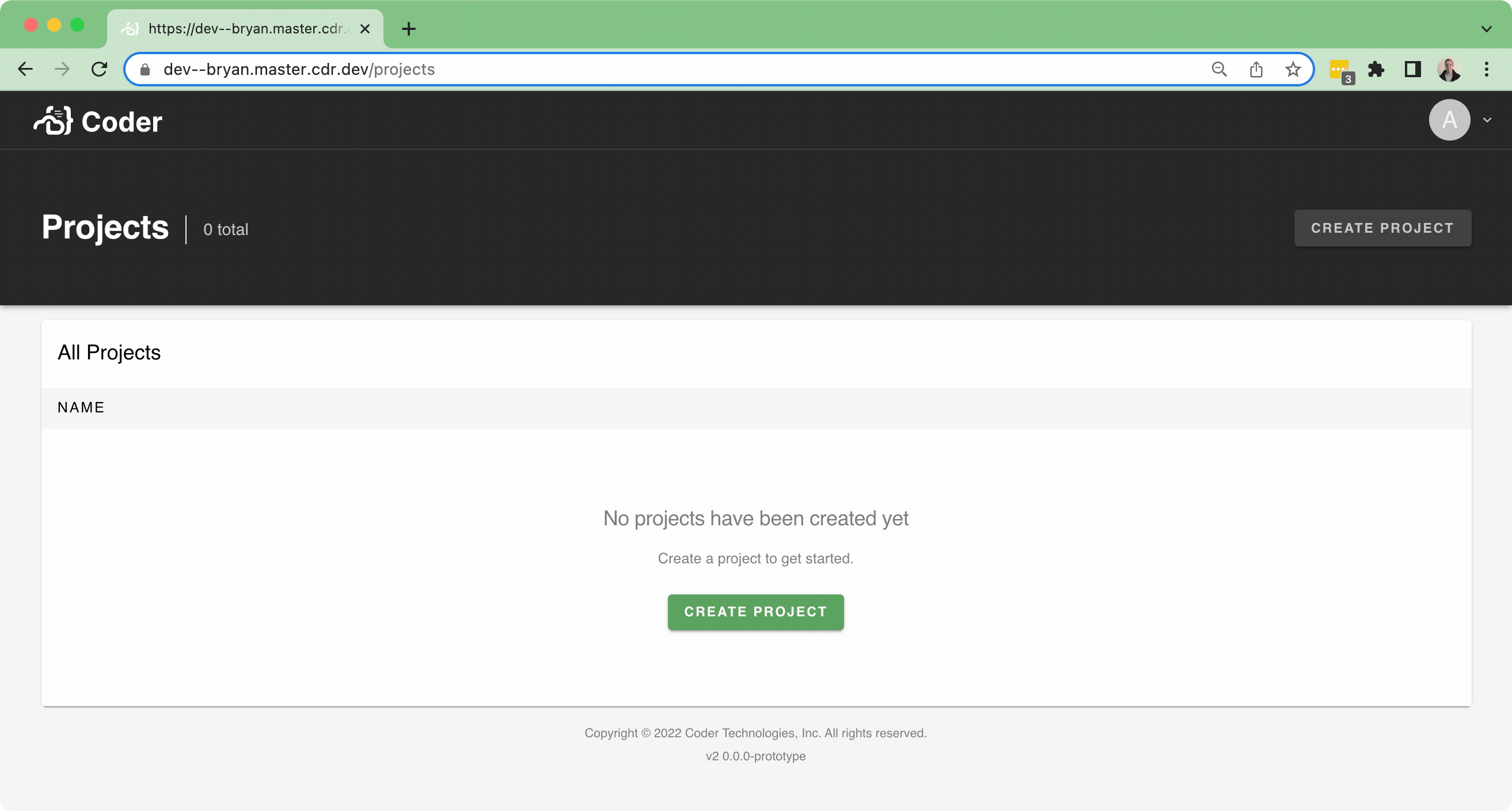
This implements a client-side redirect to land on our `/projects` route.
Prompted from discussion here: https://github.com/coder/coder/pull/60/files#r792124373
Our current FormTextField implementation requires a [higher-order component](https://reactjs.org/docs/higher-order-components.html), which can be complicated to understand.
This experiments with moving it to not require being a HoC.
The only difference in usage is that sometimes, you need to provide the type like `<FormTextField<FormValues> form={form} formFieldName="some-field-in-form" />` - but it doesn't require special construction.
* chore: Add VS Code recommended extensions
This adds extensions I feel work well for the project.
With this, a "Run on Save" extension is added that runs
"make gen" on save of query.sql to regenerate models.
* Fix formatting
* ci: Pin the golangci-lint version to prevent breakage
The main branch broke because golangci-lint released a new version.
This pins it, so hopefully it never happens again!
* Fix version string
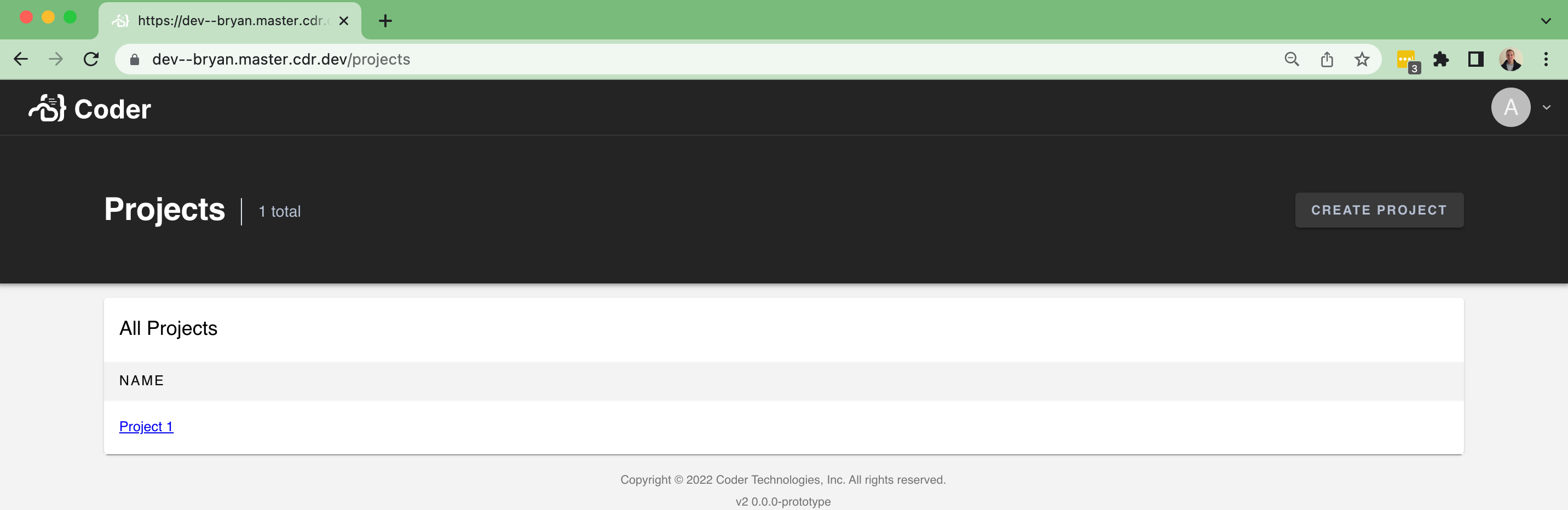
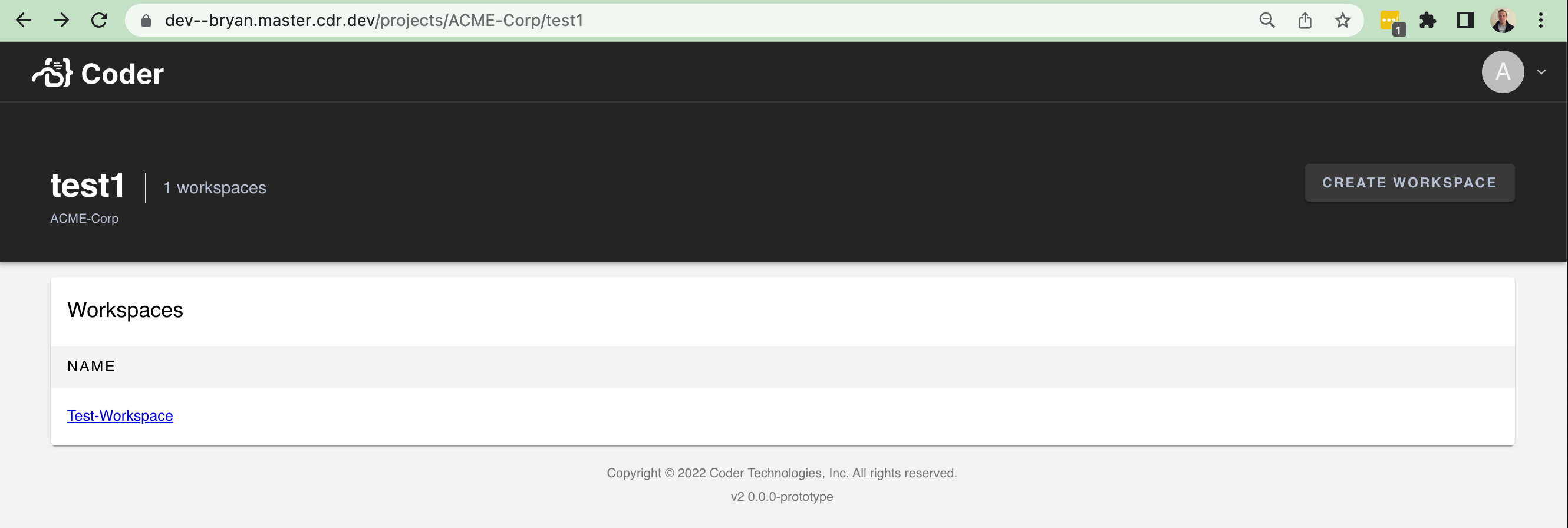
This implements a simple Project listing page at `/projects` - just a table for a list of projects:
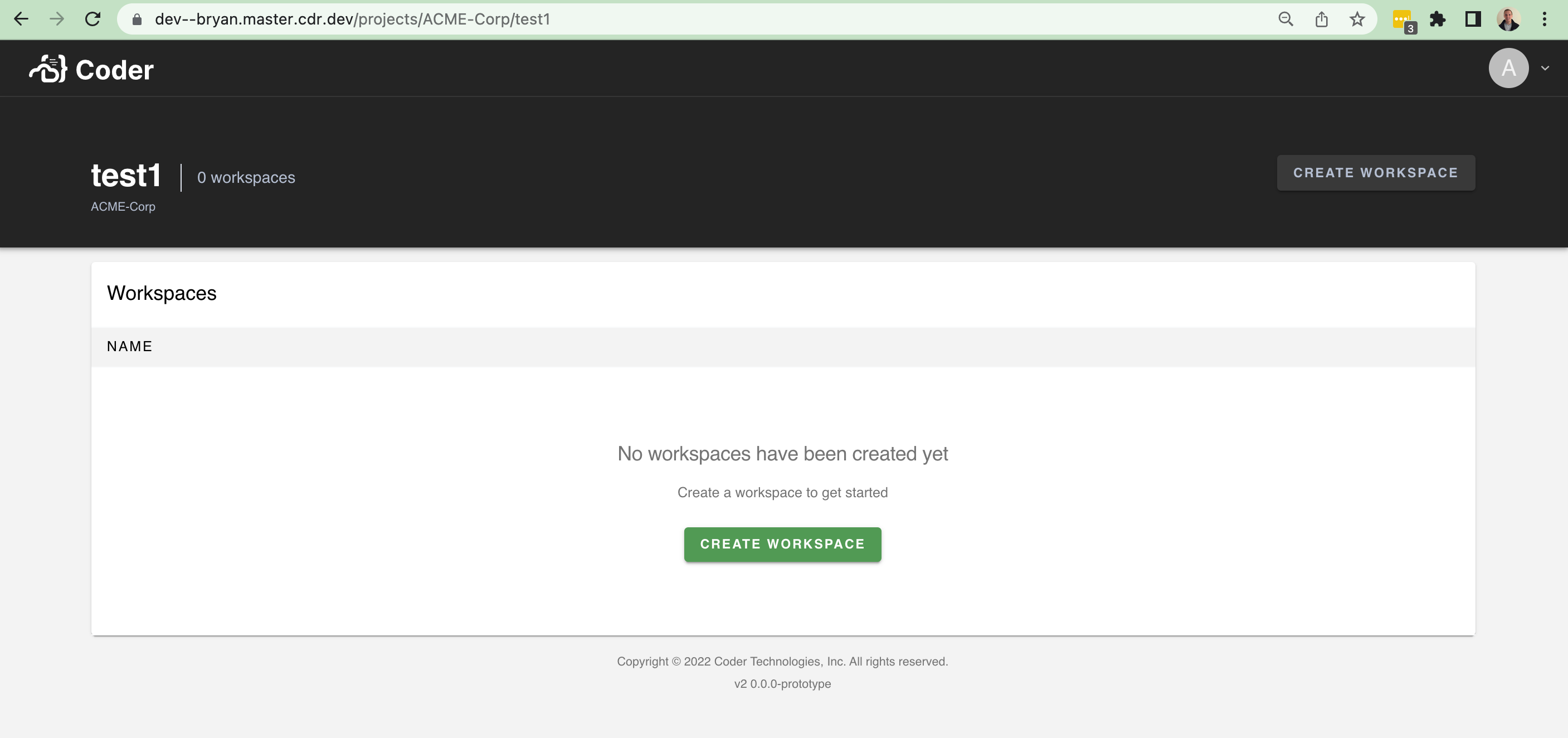
...and an empty state:
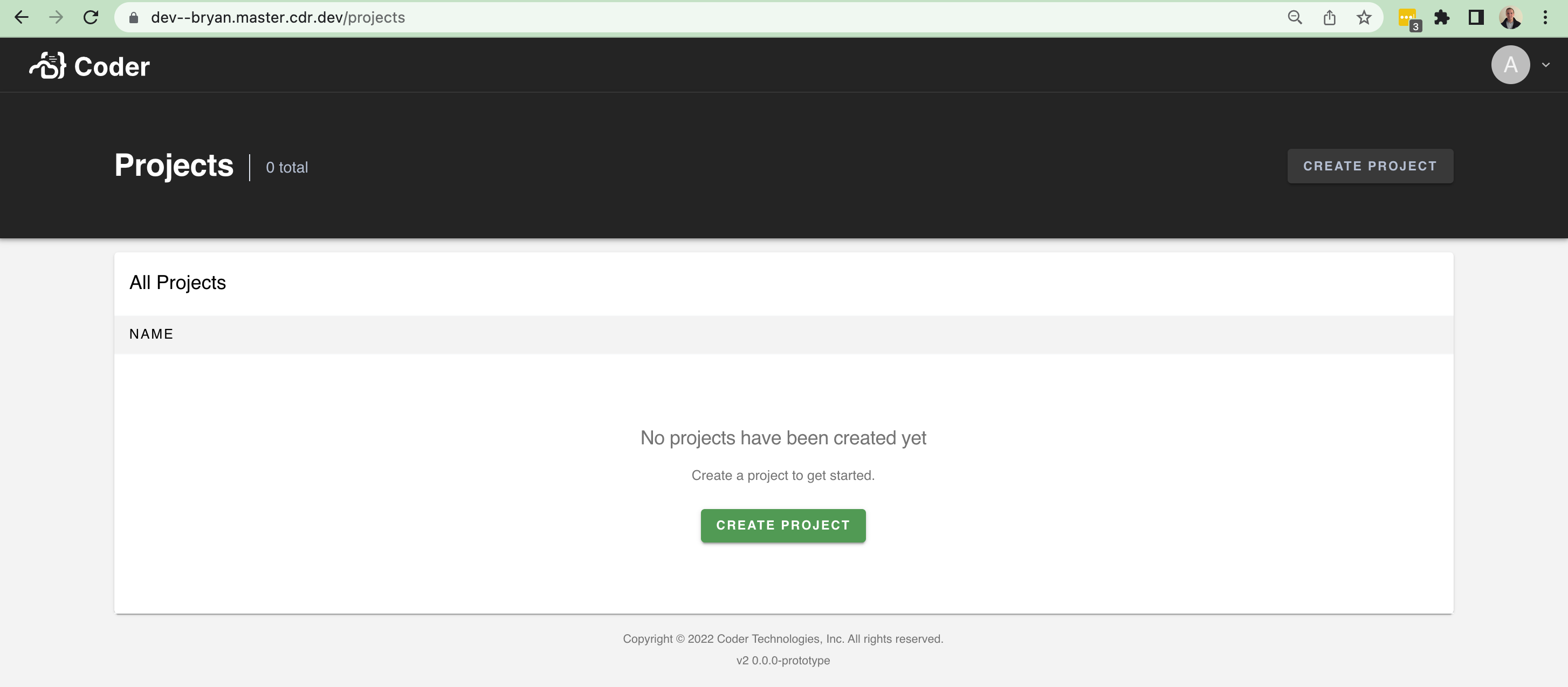
There isn't too much data to show at the moment. It'll be nice in the future to show the following fields and improve the UI with it:
- An icon
- A list of users using the project
- A description
However, this brings in a lot of scaffolding to make it easier to build pages like this (`/organizations`, `/workspaces`, etc).
In particular, I brought over a few things from v1:
- The `Hero` / `Header` component at the top of pages + sub-components
- A `Table` component for help rendering table-like UI + sub-components
- Additional palette settings that the `Hero`
#37 implemented the Sign-_in_ flow, but there wasn't a Sign-_out_ flow as part of that PR (aside from letting the cookie expire... or manually deleting the cookie...), which is obviously not ideal.
This PR implements a basic sign-out flow, along with a very simple user dropdown:
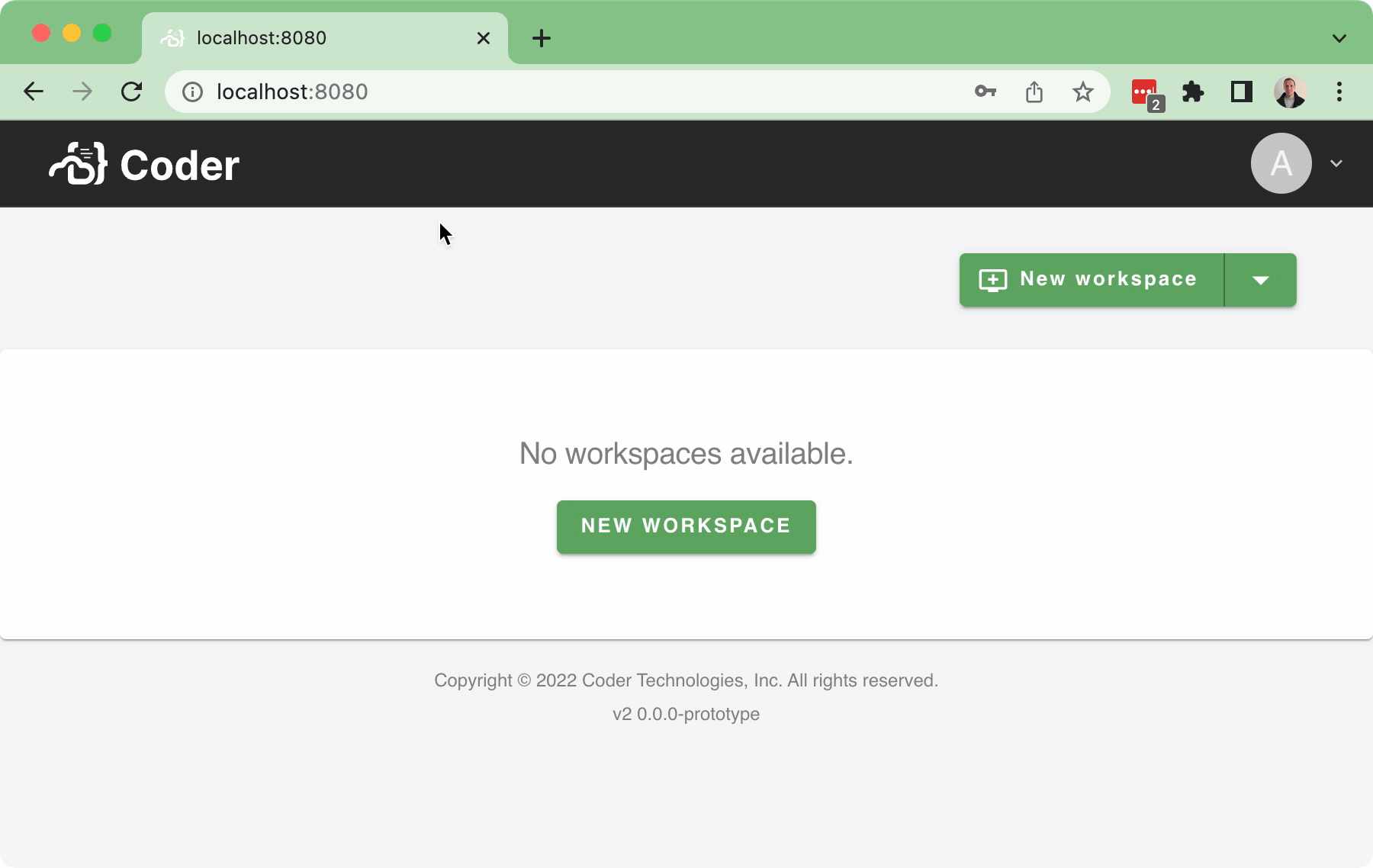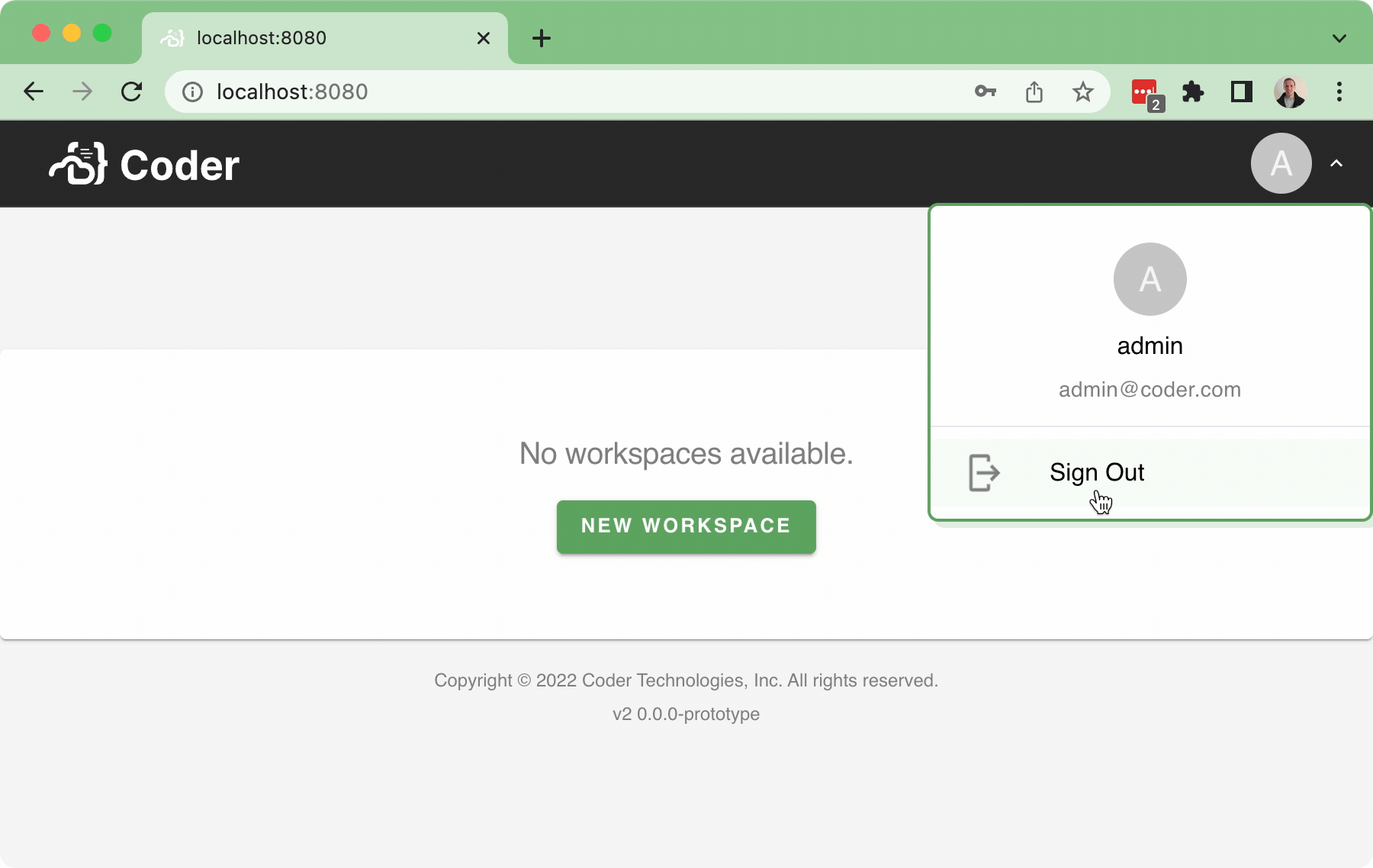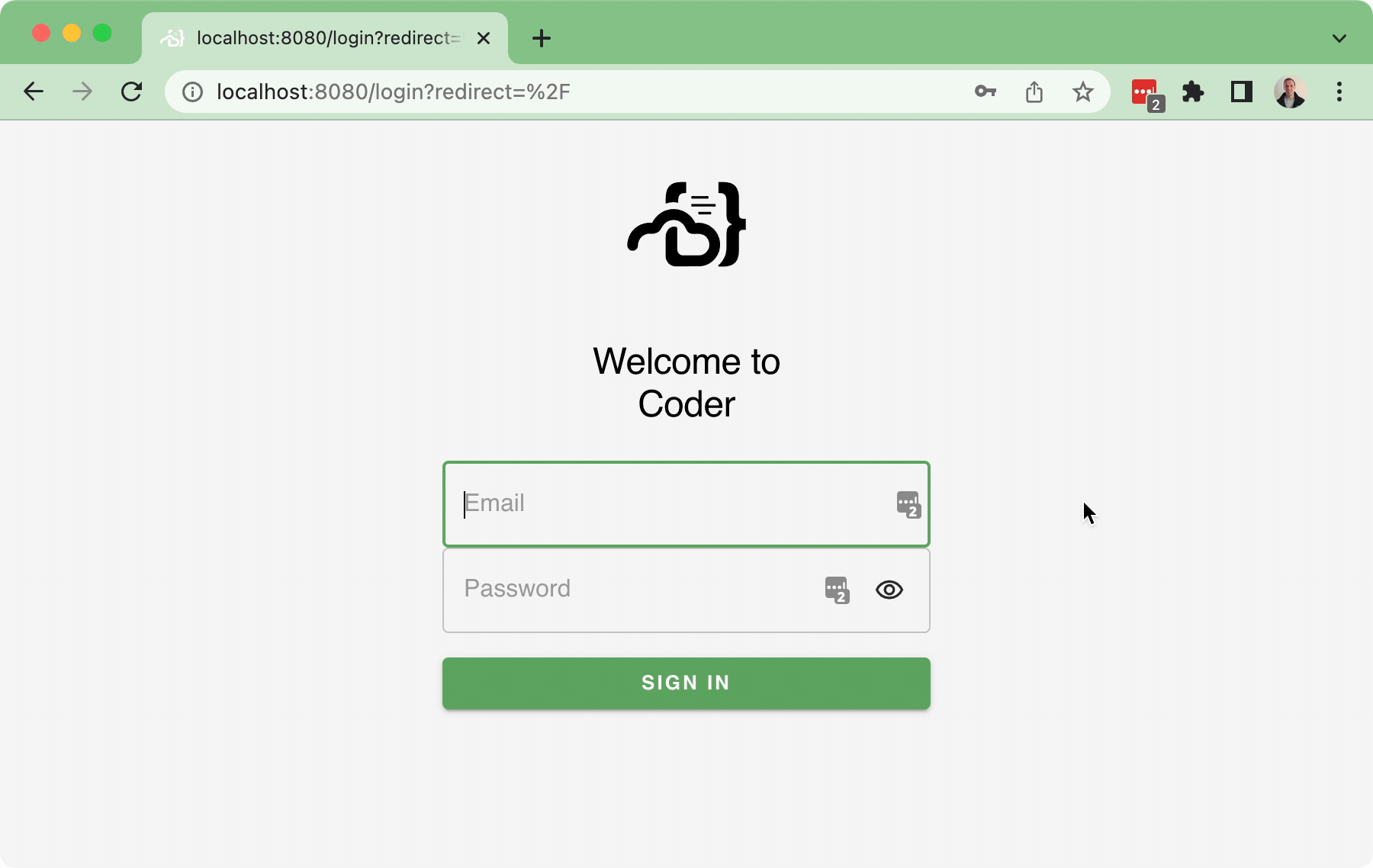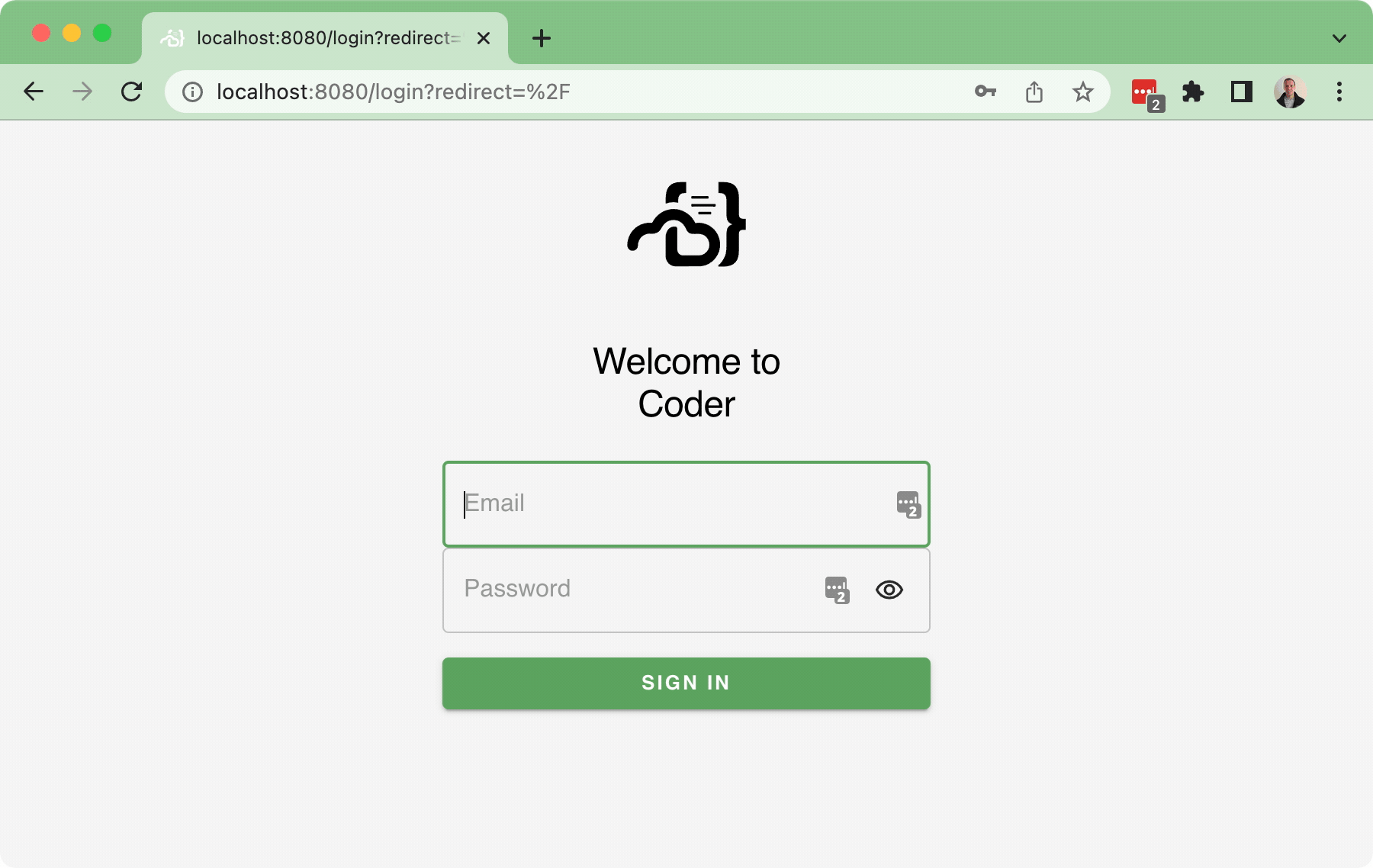
Bringing in a few pruned down components for the `<UserDropdown />` to integrate into the `<NavBar />`.
In addition, this also implements a simple back-end API for `/logout` which just clears the session token.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}